微服务架构设计
微服务是一种开发软件的架构和组织方法,其中软件由通过明确定义的 API 进行通信的小型独立服务组成。这些服务可以由各个小型独立团队负责。微服务架构使应用程序更易于扩展和更快地开发。 —AWS
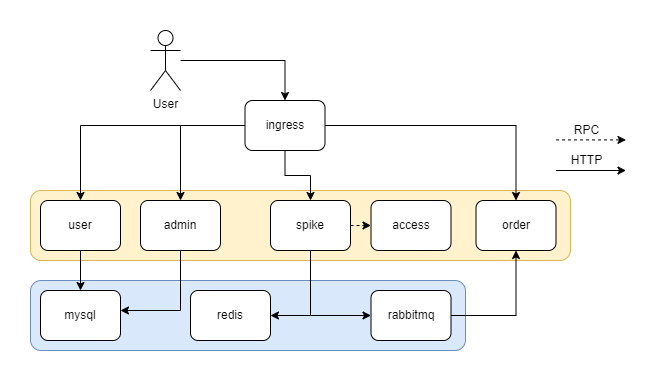
系统一共使用了如下5个微服务,相互直接通过grpc直接通信,或通过中间件间接传递数据。
-
用户(user)
- 登录
- 注册
- 刷新token
-
秒杀(spike)
- 获取秒杀token
- 秒杀
- 与准入服务通信,确认用户是否有资格参与活动
- 将订单减扣的消息发送到消息队列
-
准入(access)
- 对指定的秒杀,根据灵活的规则配置来判断用户是否有资格参与活动
-
管理(admin)
- 管理秒杀活动(CRUD)
-
订单(order)
- 查询订单
- 付款 或 取消订单
- 接收消息队列的消息,生成订单插入数据库
使用的中间件
- Mysql 数据库
- Redis 缓存
- Rabbitmq 消息队列
用户正常秒杀流程
- 登录,获取jwt token,token中保存用户id,后续请求需要携带token
- 通过前端页面点击秒杀预览,后端验证用户参入资格,准入则进入活动详情页
- 到达秒杀预设时间,点击秒杀按钮,前端发起两个请求
- 获取秒杀活动的随机token
- 使用token访问后端秒杀接口
- 若抢到,则前端轮询等待订单生成(因为订单生成是异步的)
并发优化
多级缓存
秒杀系统是一个典型的读多写少应用,1万个人抢100个商品,最后可以做的写操作只有100次,而读取可能几倍于用户数。所以使用缓存可以极大提升系统并发性能
执行环境本地缓存
使用了go-cache库,和go本身提供的map相比,它提供了过期时间和并发安全的特性。
-
准入服务中,缓存了 被构建的过滤器,这样在流量高峰到来时不需要重复构建过滤器
filterCache = cache.New(5*time.Minute, 10*time.Minute) filterCache.Set(req.SpikeId, ft, cache.DefaultExpiration) f, isFound := filterCache.Get(req.SpikeId) -
在秒杀服务中,缓存了 秒杀url随机token,而不需要每次都到redis获取,减轻redis压力,并减少网络消耗,加快处理时间
spikeUtilCache = cache.New(10*time.Minute, 20*time.Minute) type spikeUtil struct { token string limiter *rate.Limiter }
redis缓存
-
在准入服务当中,将准入服务的结果缓存到redis,基于以下两点:
- 准入结果在短时间内不会变化
- 对于某个用户,在短时间内可能多次使用到准入服务,(如反复进入秒杀界面,多次点击秒杀按钮)
redisx.SetAccess(ctx, redisId, map[string]string{"result": strconv.FormatBool(res), "reason": reason}, time.Second*30) -
在秒杀服务中缓存 秒杀url随机token,若未在本地成功获取到token则在redis中获取
randStr, err = redisx.Get(c, redisx.RandKey+spikeId)
CDN缓存
未实现
前端文件大多是静态文件,可以将其放置在云服务提供商提供的CDN服务上,来减轻流量高峰期的服务器压力,减少带宽压力,加快用户页面加载速度
多级流量过滤
对于秒杀服务来说,大多数请求最终都是失败的,要尽早抛弃,以减轻后端压力
- 令牌桶(本地环境)
对于每次秒杀活动,都会在每个秒杀服务实例本地环境创建一个令牌桶
su := &spikeUtil{
token: "",
limiter: rate.NewLimiter(defaultLimit, defaultMaxRequestNum),
}
对于超出库存量2倍的请求,直接返回503
-
库存判断(redis)
成功进入秒杀接口的请求,会首先进行库存的判断,不足则直接返回
if getRestStock(c, spikeId) <= 0 { c.JSON(200, gin.H{"status": "fail", "msg": "sold out"}) return } -
准入判断(db/redis)
调用准入服务rpc,对不准入的用户请求进行拦截
accessible, err := client.IsAccessible(c, &access.AccessReq{ UserId: user.ID, SpikeId: spikeId, }) if !accessible.Result { c.JSON(403, gin.H{"error": "no access: " + accessible.Reason}) return } -
订单判断(db)
res, err := db.InsertOrderAffair(order)在插入订单时,会将订单是否已经存在的判断加入其中,组成一个事务
可以发现,请求过滤时,将代价越小的判断放置在了前面,这样充分利用了业务特性减轻服务器压力
redis分布式锁
在此设计当中许多微服务之间的通信/同步都是由中间件来完成的,redis作为一个单线程的应用(暂不考虑集群部署的情况),天生没有并发问题
-
秒杀url随机token
由于改token是lazy load的,需要第一个拿到锁的协程进行初始化
ok, err := redisx.SetNX(c, redisx.RandKey+s.ID, randStr, s.EndTime.Sub(time.Now()))使用了redis的SetNX功能,当key不存在时,写入值,否则失败
-
库存初始化
与token初始化同理
ok, err := redisx.SetNX(ctx, redisx.SpikeStoreKey+spikeId, numStr, s.EndTime.Sub(time.Now())) -
加减预扣库存lua脚本
if (redis.call('exists', KEYS[1]) == 1) then local stock = redis.call('get', KEYS[1]); if (stock - KEYS[2] >= 0) then local leftStock = redis.call('DecrBy', KEYS[1], KEYS[2]); return leftStock; end; return -1; end; return -1;redis支持lua脚本,lua脚本中的命令将被视为一个整体运行,所以我们可以将其看作一个简单的事务
如此保证了数据访问的互斥性,不会出现超卖
消息队列
秒杀系统的典型特征之一就是短时间的瞬时流量,会导致数据库访问压力骤增,为此,我们使用了rabbitmq消息队列,来让这些流量平滑流到数据库中,起到削峰填谷的作用,异步化用户请求
// 生产者
err = sender.Publish(&order.OrderInfo{
UserId: user.ID,
SpikeId: spikeId,
Quantity: 1,
})
// 消费者
func dealMqOrder(ch <-chan *order.OrderInfo) {
go func() {
for info := range ch {
// 判断订单是否存在
o := &orm.Order{
UserID: info.UserId,
SpikeID: info.SpikeId,
Quantity: int(info.Quantity),
State: orm.OrderOrdered,
CreateTime: time.Now(),
}
res, err := db.InsertOrderAffair(o)
log.Println("success create id: " + o.ID)
}
}()
}
singleflight
在初始化库存或者随机url token时,都需要访问数据库获取spike数据,因为此时redis为空,在并发的流量下,会导致众多的请求打到数据库(缓存击穿)导致数据库崩溃,而且从逻辑上考虑,每个请求访问的其实是相同的数据,完全可以做到复用请求的结果。因此使用singleflight
spike, err := loader.Do(spikeId, func() (interface{}, error) {
spike, err := db.GetSpikeById(spikeId)
if err != nil {
return nil, err
}
return spike, nil
})
构建&部署
kubernetes & helm 部署
kubernets
Kubernetes是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制。 —k8s中文社区
我们的微服务完全运行在容器化的环境中,核心程序都被部署到k8s中,中间件(mysql、redis、rabbitmq)不在k8s中运行(但在docker中)
容器化的环境抹平不同操作系统、硬件架构上的差异,让应用可以轻松运行。
k8s提供了重要的服务发现、负载均衡、流量转发等功能。
由于没有多台机器运行一个标准的Kubernetes,我们使用了更为轻量的k3s(一个符合Kubernetes标准的发行版)
kubernets 安装
只需要一行命令即可启动一个单节点的k3s
curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn sh -
再安装一些辅助工具
snap install kubectl --classic
snap install helm --classic
helm
Helm 帮助您管理 Kubernetes 应用—— Helm Chart,即使是最复杂的 Kubernetes 应用程序,都可以帮助您定义,安装和升级。
如果将k8s看作一个操作系统(如ubuntu),那么helm可以看成这个操作系统的包管理器(如ubuntu的apt)。helm可以帮助定义、部署、升级一个k8s应用,还提供了诸如金丝雀发布这样的高级功能
helm chart中使用了
- 5个deployment,分别对应5个微服务
- 5个service,分别对应5个deployment
- 1个statefulset,启动了1个nginx,让用户可以访问前端文件
- 1个configmap,为服务提供配置文件,并且支持热更新
- ingress,提供路由转发和负载均衡功能,将用户的请求,通过路径区别分发到对应的微服务
- k3s默认使用traefik,提供了轮询负载均衡
在value.yaml中,只要定义好微服务的镜像启动命令和参数,已经服务端口,即可创建对应的deployment、service
microservices:
- name: access-service
replicaCount: 1
image: registry.cn-qingdao.aliyuncs.com/adpc/spike-access-service:latest
command:
- /access-service
- --rpc-port=8081
- --config-path=/configs/config.yaml
service:
- 8081
- name: spike-service
replicaCount: 2
image: registry.cn-qingdao.aliyuncs.com/adpc/spike-spike-service:latest
command:
- /spike-service
- --port=8080
- --config-path=/configs/config.yaml
- --access-endpoint=spike-access-service.default.svc:8081
service:
- 8080
# ...
在ingress中定义了host,已经路径、对应的服务和端口
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: spike-backend-ingress
annotations:
kubernetes.io/ingress.class: "traefik"
spec:
rules:
- host: spike.vinf.top
http:
paths:
- path: /users
pathType: Prefix
backend:
service:
name: spike-user-service
port:
number: 8080
- path: /spike
pathType: Prefix
backend:
service:
name: spike-spike-service
port:
number: 8080
# ...
将helm chart上传到服务器后,运行helm install即可部署
helm install spike spike-chart-latest.tar.gz
docker image 构建
FROM golang:1.17 as builder
WORKDIR /app
COPY go.mod ./
COPY go.sum ./
RUN go env -w GOPROXY=https://goproxy.cn,direct
RUN go mod download
COPY cmd/ cmd/
COPY internal/ internal/
COPY pkg/ pkg/
RUN mkdir -p "bin" && \
go build -o bin/access-service cmd/access/main.go && \
go build -o bin/spike-service cmd/spike/main.go && \
go build -o bin/user-service cmd/user/main.go && \
go build -o bin/admin-service cmd/admin/main.go && \
go build -o bin/order-service cmd/order/main.go
# access
FROM debian as access
WORKDIR /
COPY --from=builder /app/bin/access-service /
USER root
# ...
- dockerfile中使用了golang:1.17作为第一层镜像,将go.mod复制到环境,并运行
go mod download自动下载依赖 - 复制代码文件
- 运行go build
- 使用debian作为发布镜像,将编译后的可执行文件复制到debian镜像中,这样可以极大减小最终镜像的尺寸
为了方便,编写了一个简单的makefile,只需要运行如下命令就可以自动完成构建和上传镜像
make build_push
中间件部署
mysql
docker run -d --restart=always --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=<passwd> mysql
redis
写入/root/redis.conf
bind 0.0.0.0
daemonize NO
protected-mode no
requirepass <passwd>
docker run -d --restart=always --name redis -p 6379:6379 -v /root/redis.conf:/etc/redis/redis.conf -d redis /etc/redis/redis.conf
rabbitmq
docker run -d --restart=always --name rabbitmq -p 15672:15672 -p 5672:5672 -e RABBITMQ_DEFAULT_USER=<username> -e RABBITMQ_DEFAULT_PASS=<passwd> rabbitmq:management