缓存
缓存原理与作用
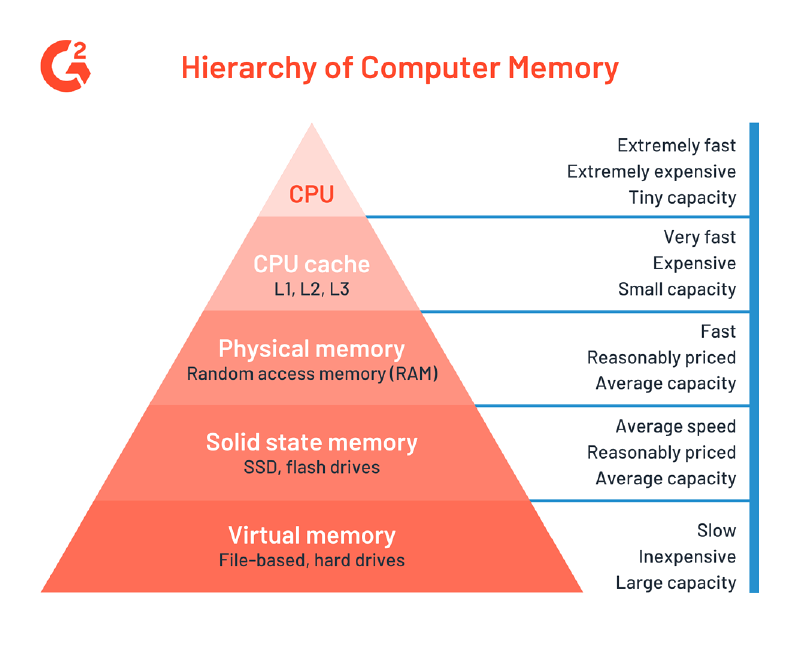
起初缓存(cache)指的是在cpu和内存之间放置一个更高速的储存器(但更小也更昂贵),如果数据因之前的操作已经读取而被暂存其中,则下一次访问的开销会小很多。原理基于"程序执行与数据访问的局域性行为",又分为
- 时间局部性,刚刚被访问的数据,有更大的概率被访问
- 空间局部性,在被访问数据附近的数据,更可能被访问
import "testing"
func TestI(t *testing.T) {
var arr [10000][10000]int
sum := 0
for i := 0; i < len(arr); i++ {
for j := 0; j < len(arr[0]); j++ {
sum += arr[i][j]
}
}
}
func TestJ(t *testing.T) {
var arr [10000][10000]int
sum := 0
for j := 0; j < len(arr[0]); j++ {
for i := 0; i < len(arr); i++ {
sum += arr[i][j]
}
}
}
测试结果:
=== RUN TestI
--- PASS: TestI (0.04s)
=== RUN TestJ
--- PASS: TestJ (0.40s)
PASS
故意使得局部性失效时,程序运行效率变慢了10倍,可见缓存对性能有着很大提升。
现如今,缓存的概念已经被扩展,不仅仅存在与cpu中。比如
-
硬盘和内存之间的缓存(硬盘缓存)
-
硬盘和网络之间也存在缓存关系(浏览器会缓存网络资源,比如图片)
-
DNS系统中,下级dns系统会缓存最近的查询,加速dns查询
groupcache被用来当作数据库/文件缓存。
缓存替换策略
缓存主要有2个质量因素:延迟和命中率。
为了提高命中率需要收集并维护更多的信息,而这会导致缓存的延迟增加,每个替换策略都是命中率和延迟之间的折中。
常见的缓存替换策略
- 随机替换 RR
- 先进先出 FIFO
- 最近最少使用 LRU
- 最少使用 LFU,与LRU不同,基于频率统计
缓存一致性

2个缓存中都持有内存数据的副本,当一个缓存中数据被更改,另一个却得不到通知,缓存不一致。
解决一致性的方法
- 写无效
当某处的缓存被更新时,所有其他位置的缓存均无效
- 写更新
当缓存更新时,一并更新所有缓存副本
缓存问题名词解释
- 缓存穿透
- 查询一个数据库和缓存均没有数据
- 缓存击穿
- 未缓存的数据短时间被高并发访问,导致大量请求穿透缓存层,直接打到数据库
- 缓存雪崩
- 大量数据在短时间内过期,大量请求落到数据库
Simple Groupcache
groupcache是一个用go编写的高效的缓存库,旨在在某些场景下代替memcached。
groupcache最大的特点是它不提供主动取消缓存的方法(也无法主动更新)。这样的设计使得它只适合静态资源的缓存,优点是简化了设计,提高了效率。
- LRU缓存更新策略
- 热点数据多点缓存
- 未命中的缓存,加锁请求,防止多个重复请求击穿
- 使用protobuf的高效节点间通信
- 支持单机/分布式缓存
LRU 实现
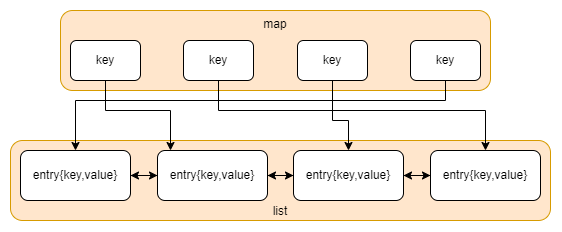
使用一个双链表和一个哈希表实现可以LRU。
get
- 使用key查找map,获取到链表节点
- 通过链表节点获取值
put
- 使用key查找map
- 存在:更新值,返回
- 容量溢出?
- 是:清除最近最少使用的缓存数据(链表头部)
- new链表节点,插入到链表尾部
- 将链表节点插入到map中
为什么在链表中存储键值对而不是单纯的值?
为了实现反向由链表找到map中存的链表节点。否则在删除最近最少使用的缓存数据时无法同步删除map中的值
import "container/list"
const NotFind = -1
type LRUCache struct {
// 容量,用key的数量简单表示
capacity int
// 链表用以维护最近最少使用的信息,最新访问过的数据被移动到队列尾部
ll *list.List
// 从key到链表元素的映射
cache map[int]*list.Element
}
// 键值对
type entry struct {
key int
value int
}
func Constructor(capacity int) LRUCache {
return LRUCache{
capacity: capacity,
ll: list.New(),
cache: make(map[int]*list.Element, capacity),
}
}
func (c *LRUCache) Get(key int) int {
// key存在,将对应的键值对移动到链表尾部
if ele, ok := c.cache[key]; ok {
c.ll.MoveToBack(ele)
kv := ele.Value.(*entry)
return kv.value
}
return NotFind
}
func (c *LRUCache) Put(key int, value int) {
// key已经存在,更新值
if ele, ok := c.cache[key]; ok {
kv := ele.Value.(*entry)
kv.value = value
c.ll.MoveToBack(ele)
return
}
// key不存在
// 容量已满删除链表头部元素
for len(c.cache) >= c.capacity {
e := c.ll.Front()
c.ll.Remove(e)
delete(c.cache, e.Value.(*entry).key)
}
// 插入链表尾部
e := c.ll.PushBack(&entry{
key: key,
value: value,
})
c.cache[key] = e
}

缓存数据抽象
type ByteView struct {
data []byte
}
func (v ByteView) Len() int {
return len(v.data)
}
func (v ByteView) ByteSlice() []byte {
cp := make([]byte, v.Len())
copy(cp, v.data)
return cp
}
groupcache原设计中,ByteView同时维护了一个字符串和一个字节数组(同一时刻只要一个有效,另一个为空),这样抹平了string和[]byte的差距,且为了防止直接从缓存中返回的切片(内部的数组)被外部更改,使用ByteSlice()拷贝了一份数据,并返回,使得缓存内部数据对外只读。
并发访问
使用sync.Mutex封装lru,使其支持并发访问
// 对lru进行封装使其支持并发读写
type cache struct {
mu sync.Mutex
lru *lru.Cache
// 直接用键值对数量来限制缓存大小,实际应该统计key value的内存占用
maxEntries int
}
func (c *cache) add(key string, value ByteView) {
c.mu.Lock()
defer c.mu.Unlock()
// 延迟初始化
if c.lru == nil {
c.lru = lru.New(c.maxEntries)
}
c.lru.Put(key, value)
}
func (c *cache) get(key string) (value ByteView, ok bool) {
c.mu.Lock()
defer c.mu.Unlock()
if c.lru == nil {
return
}
v, ok := c.lru.Get(key)
if !ok {
return
}
return v.(ByteView), ok
}
源数据获取
groupcache与memcache、redis的一大不同之处在于,它并不是以一个单独的服务运行,而是作为一个库嵌入到代码中,既作为服务器,也作为客户端。所以在获取数据的方式上,它定义了一个接口,类似下面这样。当缓存被使用时,发现数据不存在,则调用下面的接口获取源数据缓存。
type Getter interface {
Get(ctx context.Context, key string) ([]byte, error)
}
type GetterFunc func(ctx context.Context, key string) ([]byte, error)
func (f GetterFunc) Get(ctx context.Context, key string) ([]byte, error) {
return f(ctx, key)
}
这里使用了go的接口型函数编码技巧。如果直接定义一个Getter接口,则需要我们定义一个空结构体实现Getter方法,并使用。而通过如上的代码,我们可以同时使用结构体/函数作为参数,大大方便了接口的使用
type T struct {
getter Getter
}
// 直接显示类型转换使用函数
t1 := &T{getter: GetterFunc(func(ctx context.Context, key string) ([]byte, error) {
return []byte{}, nil
})}
// 或是使用符合接口的结构体
type G struct{}
func (g G) Get(ctx context.Context, key string) ([]byte, error) {
return []byte{}, nil
}
t2 := &T{
getter: G{},
}
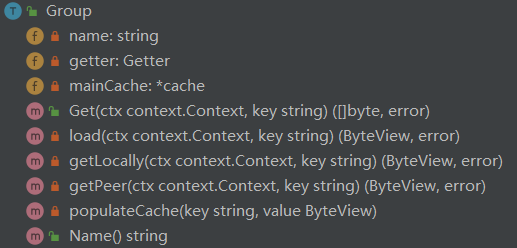
Group
group是提供服务的核心结构体,起到管理缓存,区分命名空间,联系对等点获取数据等作用。
全局变量管理多个group
var (
mu = sync.RWMutex{}
groupMap = make(map[string]*Group)
)
// A Group is a cache namespace and associated data loaded spread over
type Group struct {
name string
getter Getter
mainCache *cache
// groupcache还提供了热点数据多点缓存的功能
// hotCache *cache
}
group的结构:
缓存逻辑:
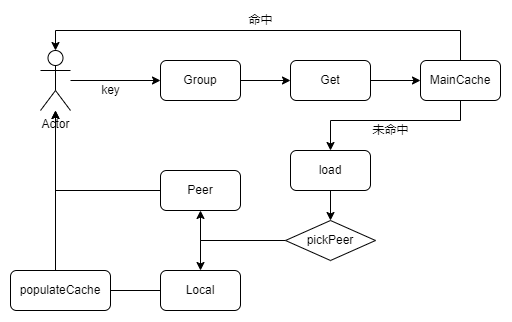
缓存命中的情况下直接返回结果。当缓存未命中,会从对等点或者用户设置的getter出获取数据。节点的选择通过一致性哈希算法实现,如果key被分配到了当前节点,节点会通过getter获取数据并缓存,否则就直接从对等点处获取直接返回。
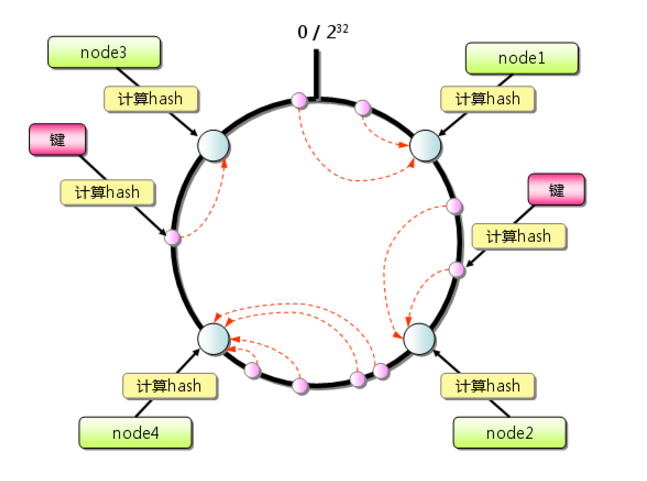
一致性哈希
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 k/n个关键字重新映射,其中 k是关键字的数量,n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。 –wiki
如果在节点选择中,采用普通哈希,则缓存会在节点数量变更时几乎全部失效,导致后端压力激增。
一致哈希尽可能使同一个资源映射到同一台缓存服务器。这种方式要求增加一台缓存服务器时,新的服务器尽量分担存储其他所有服务器的缓存资源。减少一台缓存服务器时,其他所有服务器也可以尽量分担存储它的缓存资源。 一致哈希算法的主要思想是将每个缓存服务器与一个或多个哈希值域区间关联起来,其中区间边界通过计算缓存服务器对应的哈希值来决定。
var hash = crc32.ChecksumIEEE
type Map struct {
// 在节点数量比较少的时候,容易出现节点映射不均衡的现象,可以插入多个虚拟节点
replicas int
// 虚拟节点hash值对应的实际节点
hashMap map[int]string
// 虚拟节点的哈希值,需要排序
// 通过二分查找更快找到 目标key 所归属的节点
keys []int
}
func New(replicas int) *Map {
return &Map{
replicas: replicas,
hashMap: make(map[int]string),
keys: []int{},
}
}
func (m *Map) AddNode(keys ...string) {
for _, key := range keys {
for i := 0; i < m.replicas; i++ {
// 拼接编号和节点名称,获得hash值
h := int(hash([]byte(strconv.Itoa(i) + key)))
// 插入map和keys中
m.hashMap[h] = key
m.keys = append(m.keys, h)
}
}
// 排序
sort.Ints(m.keys)
}
func (m *Map) Get(key string) string {
h := int(hash([]byte(key)))
idx := sort.Search(len(m.keys), func(i int) bool { return m.keys[i] >= h })
// 因为是个环,下标等于长度时,就折回到0,归属0号节点
if idx == len(m.keys) {
idx = 0
}
return m.hashMap[m.keys[idx]]
}
HTTP服务器&客户端
每一个节点既是服务器又是客户端,节点都开启一个http服务。
在实现http服务之前,我们需要先抽象 节点选择接口 和 节点数据获取接口
type PeerGetter interface {
Get(cxt context.Context, group string, key string) ([]byte, error)
}
type PeerPicker interface {
PickPeer(key string) (peer PeerGetter, ok bool)
}
type Group struct {
// 节点选择接口
peers PeerPicker
......
}
对于group,我们需要依赖一个实现PeerPicker接口的实例,来选择对等点获取一个PeerGetter实例,并调用Get方法,完成从对等点获取数据的能力。
接下来实现http服务器和客户端。服务器实现PeerPicker,客户端实现PeerGetter。而如果我们需要实现rpc通信,只需要修改这两个接口对应的实现,非常方便
const (
defaultBasePath = "/cache/"
defaultReplicas = 50
)
type HTTPPool struct {
basePath string
self string
// 节点选择功能
mu sync.Mutex
peers *consistenthash.Map
httpGetters map[string]*httpGetter
}
func NewHTTPPool(self string, path string) *HTTPPool {
p := &HTTPPool{
self: self,
mu: sync.Mutex{},
}
if path != "" {
p.basePath = path
} else {
p.basePath = defaultBasePath
}
http.Handle(self, p)
return p
}
func (p *HTTPPool) ServeHTTP(w http.ResponseWriter, r *http.Request) {
parts := strings.SplitN(r.URL.Path[len(p.basePath):], "/", 2)
groupName := parts[0]
key := parts[1]
// 获取group
group := GetGroup(groupName)
ctx := r.Context()
data, err := group.Get(ctx, key)
//w.Header().Set("Content-Type", "application/x-protobuf")
// 设置http请求标头为8位字节流
w.Header().Set("Content-Type", "application/octet-stream")
w.Write(data)
}
func (p *HTTPPool) PickPeer(key string) (PeerGetter, bool) {
p.mu.Lock()
defer p.mu.Unlock()
u := p.peers.Get(key)
log.Println(u)
if u == p.self {
return nil, false
}
return p.httpGetters[u], true
}
func (p *HTTPPool) Set(peers ...string) {
p.mu.Lock()
defer p.mu.Unlock()
p.peers = consistenthash.New(defaultReplicas)
p.peers.AddNode(peers...)
p.httpGetters = make(map[string]*httpGetter, len(peers))
for _, peer := range peers {
p.httpGetters[peer] = &httpGetter{baseUrl: peer + p.basePath}
}
}
// http客户端
type httpGetter struct {
baseUrl string
}
func (g *httpGetter) Get(ctx context.Context, group string, key string) ([]byte, error) {
u := fmt.Sprintf(
"%v%v/%v",
g.baseUrl,
url.QueryEscape(group),
url.QueryEscape(key),
)
res, err := http.Get(u)
log.Println(u)
if err != nil {
return nil, err
}
defer res.Body.Close()
bytes, err := ioutil.ReadAll(res.Body)
return bytes, nil
}
http内容请求标头: http Content-Type
example.com:8000/cache/test-group/key,请求的url中包括了域名,端口,起到标识作用的path,group名称,key
Protobuf
Protobuf是一个数据结构序列化库,和常见的json功能类似。
protobuf对比json:
优点:
- 序列与反序列化效率更高
- 算法优势使其对数据有压缩能力,减小带宽压力
- 不仅仅包含消息,也包含服务的定义
确定:
- 二进制序列人类不可读
- 灵活性较低
两者适合的应用场景不同,protobuf更适合内部环境,比如rpc。而json更适合web应用。
syntax = "proto2";
package protobuf;
option go_package = "../pb";
message GetRequest {
required string group = 1;
required string key = 2;
}
message GetResponse {
optional bytes value = 1;
}
protoc --go_out=. *.proto
生成对应的go代码。
原本服务的响应是放置在body中的二进制流,现在将其通过protobuf编码
分别修改请求、服务、接口
func (g *httpGetter) Get(ctx context.Context, in *pb.GetRequest, out *pb.GetResponse) error{
......
bytes, err := ioutil.ReadAll(res.Body)
err = proto.Unmarshal(bytes, out)
}
func (p *HTTPPool) ServeHTTP(w http.ResponseWriter, r *http.Request) {
.....
w.Header().Set("Content-Type", "application/x-pb")
body, err := proto.Marshal(&pb.GetResponse{Value: data})
w.Write(body)
}
type PeerGetter interface {
Get(ctx context.Context, in *pb.GetRequest, out *pb.GetResponse) error
}
singleflight
缓存击穿
- 未缓存的数据短时间被高并发访问,导致大量请求穿透缓存层,直接打到数据库
如果一个数据不在缓存中,而瞬时又有了很大的并发请求(比如秒杀活动前的一些数据),缓存会向数据库发起多次相同的请求,数据库可能因此奔溃。而singleflight通过阻塞后续同样的请求,来防止缓存击穿。
// 保存请求的返回值供其他请求使用,并用WaitGroup阻塞其他请求
type call struct {
wg sync.WaitGroup
val interface{}
err error
}
// 维护一个map,通过key找到请求
// Mutex用来保证map的线程安全
type Group struct {
m map[string]*call
mu sync.Mutex
}
// 传入一个key,和一个函数,函数只会被执行第一次
// 后来的请求会被阻塞,待第一个请求完成后,后续的请求使用相同的返回值
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
if c, ok := g.m[key]; ok {
g.mu.Unlock()
// 阻塞
c.wg.Wait()
return c.val, c.err
}
c := &call{}
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
// 执行
c.val, c.err = fn()
c.wg.Done()
g.mu.Lock()
delete(g.m, key)
g.mu.Unlock()
return c.val, c.err
}
使用时只需要代码包裹在do中,并处理一下返回值
func (g *Group) load(ctx context.Context, key string) (ByteView, error) {
val, err := g.loader.Do(key, func() (interface{}, error) {
p, ok := g.peers.PickPeer(key)
if !ok {
bv, err := g.getLocally(ctx, key)
if err != nil {
return ByteView{}, err
}
g.populateCache(key, bv)
return bv, err
}
return g.getPeer(ctx, key, p)
})
if err != nil {
return ByteView{}, err
}
return val.(ByteView), nil
}
附注
完整代码:
参考链接:
图片来源:
By Dennis - Own work, Public Domain, https://commons.wikimedia.org/w/index.php?curid=31541