
引言
在Kubernetes的官方文档介绍中,有2种方法可以实现对原生调度器的扩展
- scheduling-framework:直接编写一个完整的调度器,并替换原生的调度器,即使用scheduling-framework,在原生的调度器代码中,使用调度框架接入自定义的插件实现调度器扩展。
- scheduler extender:原生的调度器支持以Webhook的方式使用HTTP请求来连接到额外的调度器扩展,但是这种方式只支持过滤和优先排序阶段,某些调度方法无法实现(比如gang调度)。
| 优点 | 缺点 | |
|---|---|---|
| scheduling-framework | 性能好:由于插件与调度器一同编译,调度器以程序内部函数的方式直接调用插件,性能很好。扩展性好:支持更多的扩展点,可以实现更复杂的逻辑。 | 兼容性:不同的集群版本需要重新编译代码 |
| scheduler extender | 实现简单:不需要重新编译调度器,只需创建一个HTTP服务,实现调度逻辑即可。 | 性能差:调度请求需要经过 HTTP 调用,增加了调度延迟,且不能复用调度器内部的缓存,需要重新维护本地缓存,有资源浪费。 |
binpack调度算法
Binpack 算法的核心目标是尽可能将已有节点填满,避免将工作负载分散到空闲节点上。这种调度策略有助于将应用负载聚集到部分节点上,从而便于集群自动扩缩容的管理。为类似GPU算力这样的稀缺资源进行binpack调度策略,可以减少GPU资源碎片化,提示资源利用率。具体实现上,Binpack 算法会对每个可用节点打分,节点得分越高表示其资源利用率越高,从而优先选择这些节点进行 Pod 调度。
在 Kubernetes 原生调度器扩展中,Binpack 调度算法以插件的形式注入到调度流程中,主要应用于节点打分阶段。在调度过程中,插件会考虑节点的剩余资源,并根据配置的各资源权重计算节点得分。
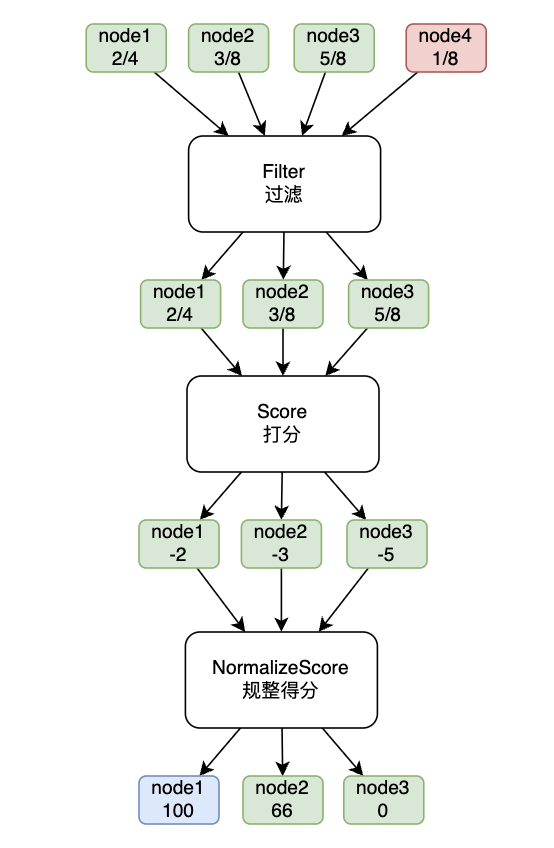
以下图为例,有4个节点,每个节点可用的资源(例如GPU卡)分别为2、3、5、1。在筛选阶段,节点4就会被淘汰,随后进入我们的打分插件为节点进行打分,并规整到调度器的标准分数范围0-100,最后节点1得分最高胜出。
scheduling-framework

调度器在进行 “Pod 调度” 时会依次经历多个环节,例如:
- QueueSort:给待调度 Pod 排队;
- Filter:筛掉不符合要求的节点;
- Score:对剩余可调度节点打分;
- Reserve:保留资源;
- Permit:自定义准入控制;
- Bind:最终在节点上创建 Pod;
- 其它扩展点:Prefilter、PostFilter、PostBind …
我们可以选择在任何环节注入自定义插件,以达到定制化调度策略的目的。
对于binpack调度只需要在Score阶段引入插件即可实现。
代码解析
演示的代码在scheduler-plugins-binpack仓库的plugin/binpack分支下,该分支基于release-1.23分支切出,只支持k8s 1.23版本。
package binpack
import (
"context"
"fmt"
"math"
"k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/klog/v2"
"k8s.io/kubernetes/pkg/scheduler/framework"
)
type BinPack struct {
handle framework.Handle
}
// 确保 BinPack 实现了 framework.ScorePlugin 的接口
var _ = framework.ScorePlugin(&BinPack{})
// Name is the name of the plugin used in the Registry and configurations.
const Name = "Binpack"
func (bp *BinPack) Name() string {
return Name
}
// Score 插件的核心,给每个节点打分
func (bp *BinPack) Score(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
// 通过 handle 可以获取当前节点的快照信息
nodeInfo, err := bp.handle.SnapshotSharedLister().NodeInfos().Get(nodeName)
if err != nil {
return 0, framework.NewStatus(framework.Error, fmt.Sprintf("getting node %q from Snapshot: %v", nodeName, err))
}
// 根据节点剩余 CPU 进行打分
return bp.score(nodeInfo)
}
// score 函数,根据剩余 CPU 得到“反向得分”
func (bp *BinPack) score(nodeInfo *framework.NodeInfo) (int64, *framework.Status) {
// 剩余可分配 = 可分配CPU - 已分配CPU
rest := nodeInfo.Allocatable.MilliCPU - nodeInfo.Requested.MilliCPU
// 将分数设为 -rest,剩余越多,分数越低
score := -rest
klog.Infof("node %s get score %d", nodeInfo.Node().Name, score)
return score, nil
}
// ScoreExtensions 返回一个实现了 NormalizeScore 的对象
func (bp *BinPack) ScoreExtensions() framework.ScoreExtensions {
return bp
}
// NormalizeScore 将各节点的原始分数映射到 [0,100] 区间
func (bp *BinPack) NormalizeScore(ctx context.Context, state *framework.CycleState, p *v1.Pod, scores framework.NodeScoreList) *framework.Status {
// 找到最高和最低分
var highest int64 = math.MinInt64
var lowest int64 = math.MaxInt64
for _, nodeScore := range scores {
if nodeScore.Score > highest {
highest = nodeScore.Score
}
if nodeScore.Score < lowest {
lowest = nodeScore.Score
}
}
// oldRange = 原始分数范围
oldRange := highest - lowest
// newRange = 框架允许的分数范围
newRange := framework.MaxNodeScore - framework.MinNodeScore
// 将所有节点 score 映射到 [MinNodeScore, MaxNodeScore]
for i, nodeScore := range scores {
if oldRange == 0 {
// 如果所有节点分数都相同,就给一个默认分数
scores[i].Score = framework.MaxNodeScore
} else {
scores[i].Score = ((nodeScore.Score - lowest) * newRange / oldRange) + framework.MinNodeScore
}
}
return nil
}
// New 用于在插件工厂中创建 BinPack 实例
func New(args runtime.Object, h framework.Handle) (framework.Plugin, error) {
return &BinPack{
handle: h,
}, nil
}
Score
- 获取节点信息
nodeInfo,拿到剩余 CPU rest - 令
score = -rest。这样剩余资源越多,得分越小,越不优先。
NormalizeScore
- 找到所有节点中最高与最低原始分数。
- 按照 线性插值 的方法,将
[lowest, highest]区间映射到[0, 100]区间。
随后在cmd/scheduler/main.go中接入插件
func main() {
// Register custom plugins to the scheduler framework.
// Later they can consist of scheduler profile(s) and hence
// used by various kinds of workloads.
command := app.NewSchedulerCommand(
//......
app.WithPlugin(binpack.Name, binpack.New),
)
code := cli.Run(command)
os.Exit(code)
}
构建镜像
-
进入项目目录
-
执行
make local-image
-
tag并push localhost:5000/scheduler-plugins/kube-scheduler:latest 镜像(可选)
部署
以下步骤使用kind环境进行演示
- 导入调度器镜像
kind load docker-image localhost:5000/scheduler-plugins/kube-scheduler:latest
- 进入控制集群机器
docker exec -it $(docker ps | grep control-plane | awk '{print $1}') bash
- 备份kube-scheduler
cp /etc/kubernetes/manifests/kube-scheduler.yaml /etc/kubernetes/kube-scheduler.yaml
- 创建
/etc/kubernetes/sched-cc.yaml文件,在配置文件中启用Binpack插件
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
leaderElection:
# (Optional) Change true to false if you are not running a HA control-plane.
leaderElect: false
clientConnection:
kubeconfig: /etc/kubernetes/scheduler.conf
profiles:
- schedulerName: default-scheduler
plugins:
score:
enabled:
- name: Binpack
- 修改调度器配置/etc/kubernetes/manifests/kube-scheduler.yaml,在其中挂载新的调度器配置,并在flag中引入配置,同时修改镜像为包含Binpack调度器插件的镜像
16d15
+ - --config=/etc/kubernetes/sched-cc.yaml
17a17,18
- - --kubeconfig=/etc/kubernetes/scheduler.conf
- - --leader-elect=true
19,20c20
+ image: localhost:5000/scheduler-plugins/kube-scheduler:latest
---
- image: registry.k8s.io/kube-scheduler:v1.23.0
50,52d49
+ - mountPath: /etc/kubernetes/sched-cc.yaml
+ name: sched-cc
+ readOnly: true
60,63d56
+ - hostPath:
+ path: /etc/kubernetes/sched-cc.yaml
+ type: FileOrCreate
+ name: sched-cc
- 配置修改后,集群中的kube-scheduler会自行重启
详细流程可以参考:https://github.com/kubernetes-sigs/scheduler-plugins/blob/master/doc/install.md#as-a-single-scheduler-replacing-the-vanilla-default-scheduler
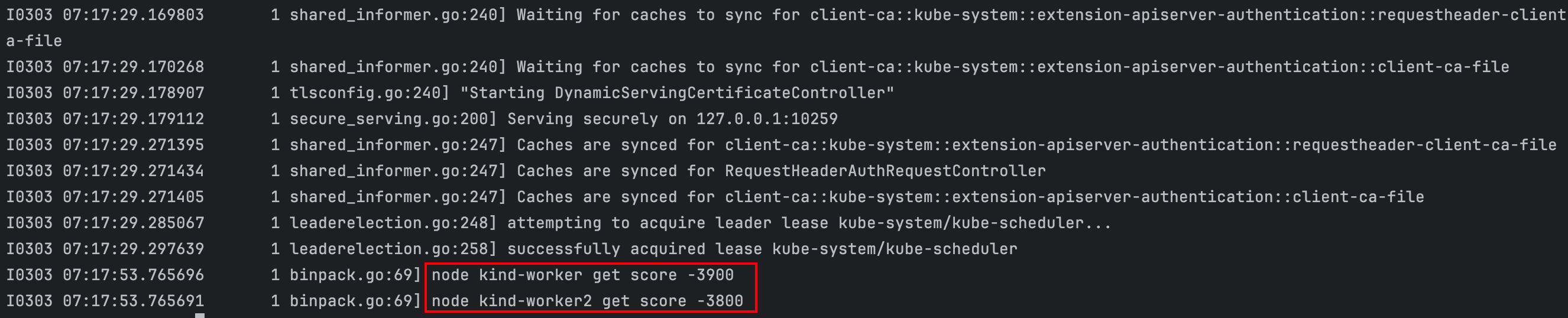
运行示例:
总结
在本文中,我们比较了两种 Kubernetes 调度器扩展方式:Scheduling Framework 和 Scheduler Extender。
- Scheduling Framework 插件直接与调度器进程内的生命周期钩子结合,无需额外的 HTTP 通信,性能好、扩展点多,适合对 Kubernetes 版本有可控的场景。
- Scheduler Extender 无需重编译调度器,仅以 HTTP 请求的方式进行 Filter、Prioritize 扩展,部署更为灵活,但性能和可扩展性相对受限。
此外,我们通过一个 Binpack 算法 的示例(Score Plugin 形式)说明了如何在 Scheduling Framework 中注入“资源打包”逻辑,使调度器倾向于将工作负载集中到已有使用率较高的节点,从而减少资源碎片、提高资源利用率。该插件主要包含两个核心点:
- Score:基于“剩余资源越少,分数越高”的思路;
- NormalizeScore:将原始分数映射到调度框架所需的 0,1000, 1000,100 区间。
在实际应用中,类似 GPU 等稀缺资源的 Binpack 策略更具价值,可避免 GPU 过度分散和浪费。 若想进一步扩展,可结合 Prefilter、Filter、Reserve、Permit、Bind 等更多调度阶段,打造更复杂的调度场景。
附录
- Kubernetes 调度框架和扩展器的比较
- 官方scheduler-plugins示例,更多复杂的调度实现可以参考